…and it is called active learning, and it’s not very impressive. The connection is pretty simple to see.
Let’s start by outlining what a “recursively self-improving AI” would look like.
To start, there’s some code. It gets compiled into an executable function. This is then evaluated, giving some score or feedback signal (this is the thing that is improving). Based on the feedback signal, the executable writes some new code…
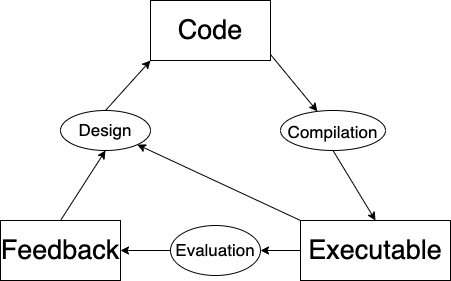
A process which repeats ad infinitum. Hopefully this picture of recursive self-improvement is generic and natural enough to be uncontroversial.
Now, let’s connect this to active learning.
The key thing to understand is that a machine learning program is based on both code and data. (Unlike in traditional programming, in which a program is based only on code.) The “code” part of a machine learning program specifies the architecture, input and output transformations, etc. But the actual neural network – the executable function – is reliant upon the dataset, too. After all, that’s where the weights come from: they are the result of running an optimizer against the dataset, and so will depend upon the choice of dataset. The learning algorithm is analogous to the compiler, in that it transforms a specification into an executable.
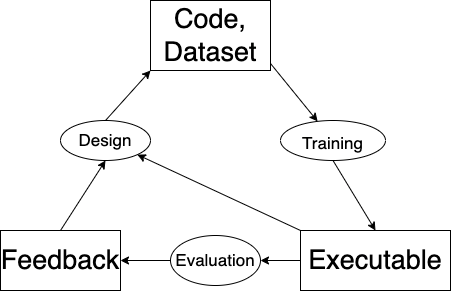
Furthermore, note that this setup gives us a straightforward way to improve the function. Since our executable is specified by our code + dataset, an improvement to either of these two aspects represents an improvement in the overall function. So there’s no need to ever change the code. We can just add data to the dataset.1
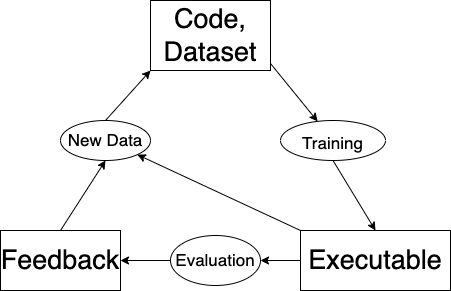
And there we have it: active learning.
The above breakdown is a bit abstract, so let me make things more concrete with a quick example. What would it look like to apply active learning to GPT-3, thereby transforming it into a recursively self-improving AI?
Imagine if you opened up GPT-3 and, in a surprising role reversal, it gave you a prompt.
“Jane has eight apples. Charlie ate half of her apples. Now Jane has”-
A small text box pops up on your screen. You dutifully type “four”, and press enter. This brand new context/next-word pair gets dumped into a giant data warehouse, alongside thousands of similarly-collected pairs, and also alongside the original GPT-3 dataset (i.e. assorted text scraped from the internet). Overnight, OpenAI finetunes GPT-3 on this new, enlarged dataset, and tomorrow, GPT-3 has become capable of doing math with apples.
What’s the takeaway here?
One possible reaction is to project your intuitions about recursively self-improving AI onto active learning algorithms, and become concerned. People have been studying these algorithms for years, unknowingly mere inches from a world-ending singularity. If more progress is made here, it could all be over. (More seriously: active learning is pretty underappreciated, given how fundamental it is, and it would be good to see more people tackling it seriously.)
But we should also reverse this: take a look at active learning, in order to improve your intuitions about recursively self-improving AI. People have been studying these algorithms for years, and haven’t unleashed a superintelligence. Why? Mainly, the answer is that current active learning algorithms are bad, and as a result self-improvement happens quite slowly. Self-improvement at a slow enough pace is not dangerous, or even particularly impressive.
But this begs a second question: why is it slow, when everything else is so fast? No matter how bad the current algorithms are, shouldn’t the overall process still bianually double in speed alongside everything else, following Moore’s Law? The answer is no, thanks to that pesky step 3: “get feedback”. For most real-world problems, getting feedback is a real-world activity. Some examples are getting a human label (GPT-3), a physical reaction (robotic control), or an artist drawing an image (DALLE-2). Since these activities rely on non-computational actions, they are not sped up by computational improvements. Since everything else is accelerated, this step will always eventually become the bottleneck of the whole process.
One final thought. Recursive self-improvement alone is nothing to fear. This bottleneck should make you a bit skeptical of “sudden takeoff” narratives. Data-gathering will always need to be a process of real-world interaction, and that process will necessarily be slow (relative to compute speeds). Active learning can certainly get much more efficient than it is now, but it seems plausible that there are limits on how quickly it is possible to learn. Any agent still needs to see a certain minimum amount of data in order to reach a particular correct conclusion; covering various cases, ruling out counterfactuals, etc.
Thanks for reading. Follow me on Substack for more writing, or hit me up on Twitter @jacobmbuckman with any feedback or questions!
Many thanks to Alexey Guzey for the discussion that inspired this post.
-
I’m making an important assumption here: adding data to a dataset will improve the quality of the function that we learn. This is empirically almost always true in deep learning, although there are some exceptions, in particular when the model is too small. ↩